
はじめに
はじめまして、CRO技術部の飯村です。 本記事では機械学習(AI)をシステム開発に組み込み、継続的/効率的に開発運用を行うための概念である「MLOps」についてご紹介します。
MLOps とは
MLOpsの考え方は、ML(Machine Learning、機械学習)にDevOpsという概念を持ち込むところからできています。
DevOpsとは、システムの開発・運用の工数を自動化によって削減するための考えです。 DevOpsを支える仕組みとして、CI/CDという手法が存在します。 CIとはContinuous Integration(継続的インテグレーション)の略であり、アプリケーションのソースコード変更に応じて定期的にテストを行い本番環境に適用できるようにするワークフローを自動で回せるようにする仕組みのことです。 CDとはContinuous Delivery/Continuous Deployment(継続的デリバリー/継続的デプロイメント)の略であり、開発者が行ったアプリケーションの変更を自動で本番環境に行うようにする仕組みのことです。
ここで話題をMLOpsに戻します。MLOpsを実現するためには、DevOpsの概念に加えて機械学習の分野での「学習」および「推論」に関連する要素を管理する必要があります。 機械学習において「推論」とは大雑把に言えば「データをAIモデルに読み込ませて、結果を受け取ること」で、「学習」は「大量に入力されるデータによってAIモデル内部のパラメータを更新し、AIモデルの精度を高めていく」ことです。
DevOpsでは
- ソースコード
- インフラ
- アプリの動作環境
- CI/CDパイプライン
といった要素を管理する必要がありますが、MLOpsではそれに加えて
- 学習に使ったデータ
- AIモデル
- 学習の履歴・設定
等の要素も管理する必要があります。
ソースコード等はどんなに悪い状態でも「使われているものを読めばわかる」ものですが、AIモデルはバイナリデータなので、管理をしておかないと後からその中身を確認することは難しくなってしまいます。そうなるとAIモデルやそれを用いたシステムを効率的に開発・運用することができず、システムをビジネス上で迅速に運用することが困難となってしまいます。
このようにMLOpsを実現するには多くの要素を管理された状態下に置いたうえで自動化を進める必要があります。
MLOpsのワークフロー図
MLOpsのワークフロー例を以下に示します。
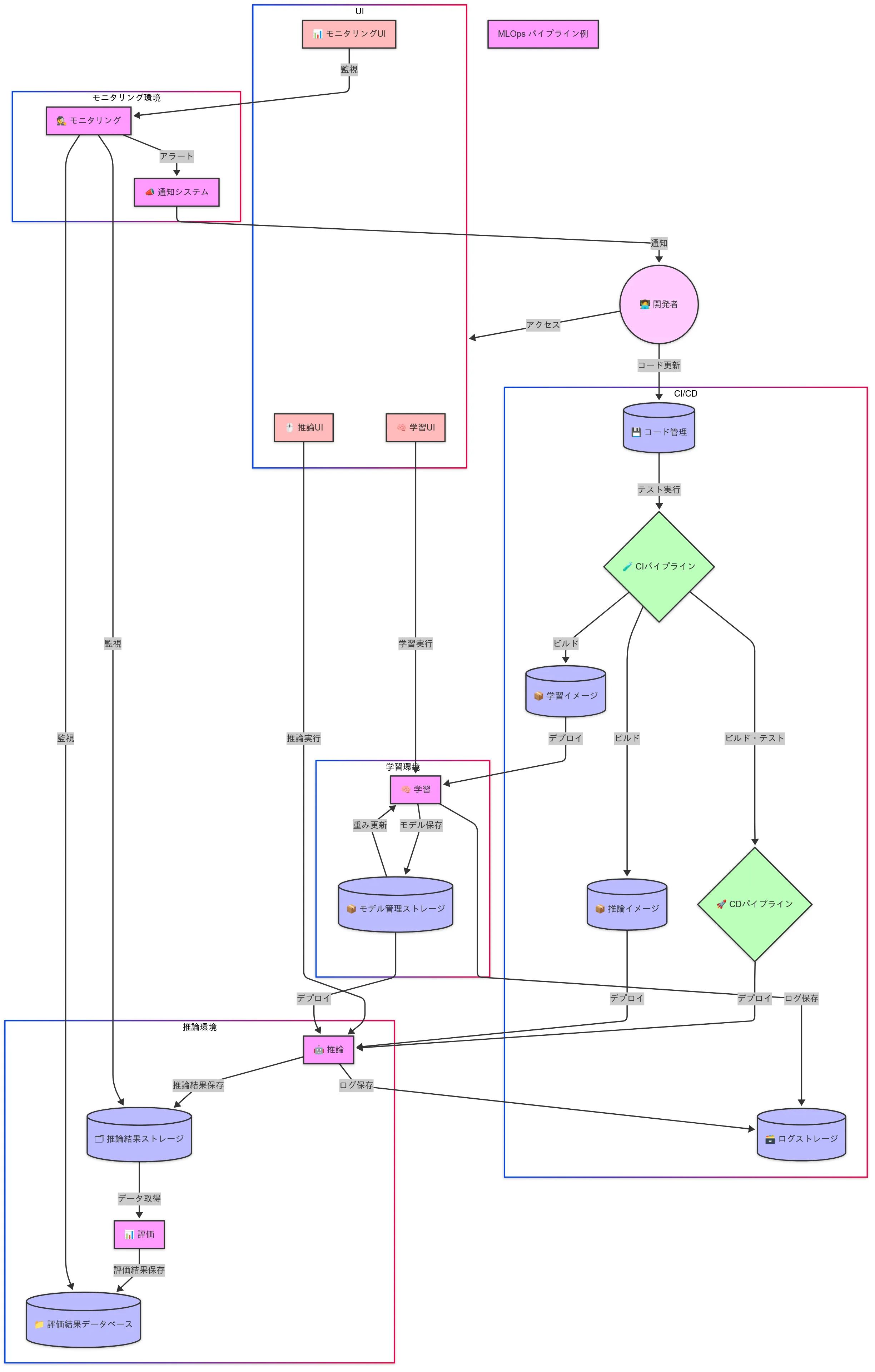
この図はMLOpsのワークフローをいくつかの環境に区切って表現しています。
- AIモデルの学習を担当する学習環境
- AIモデルで推論を行う推論環境
- 学習/推論を行うためのアプリのCI/CD
- AIモデルの性能を監視するモニタリング環境
- 開発者がこれらの環境にアクセスするためのUI
これらがどのように実際に連携するかを、以下のようなシステムを例として簡単に説明します。
- 定期的に外部から画像をAIモデルに入力して人の検出を行う
- 人の検出結果は推論結果ストレージに保存される
- 検出結果から人の数等を評価し、評価結果データベースに格納する評価アプリが存在する
- 推論や学習を行うためのアプリケーションの動作環境はソースコードから「推論イメージ」「学習イメージ」としてビルドされる
- AIモデルの学習結果はモデル管理ストレージに保存される
- 推論/学習を行った際のアプリのログを集積するログストレージが存在する
- 評価結果データベースや推論結果ストレージの内容を定期的に監視するモニタリングアプリが存在する
- モニタリングアプリはメール等の通知システムと連携しており、異常を検知すると開発者に通知を送る
- モニタリング環境/推論環境/学習環境にアクセスするためのUIが存在する
この場合、例えば以下のようなフローが発生しえます。
- 定期的に実行されるモニタリングアプリから推論結果の異常通知を開発者が受け取る
- 開発者が通知を確認したところ、推論結果として格納される「人」のデータ量が以前と比べて大きく減っていることがわかる
- 開発者はログ/ストレージ/データベースを確認し、異常の原因を特定する
- 推論用のコード中で、データベースに推論結果を格納する部分にバグを発見する
- ソースコードを修正し、CI/CDパイプラインを流して推論イメージ/学習イメージを更新する
- 今までどおり正常に推論環境が動作していることを確認する
- 1.に戻る
このようなアプリに原因がある場合以外にも、外部から入力される画像データの傾向が変化するような入力データのずれが発生し異常が検知されることがあります。 そのような場合でも原因を特定してコードを修正したり、AIモデルに再学習を行ったりすることで修正を行うことができるようになっています。
MLOpsのワークフローの一部を実際に動かしてみる
MLOpsのワークフローを構成する要素のうち、学習環境(学習及びモデル管理の部分)を実現するためのツールとして、「MLflow」が存在します。 MLflowのクイックスタート1をなぞることでちょっとした学習環境の機能を試してみることが可能です。
MLflowはpythonでライブラリが提供されており、pipを用いてインストールすることができます。 また、チュートリアルで用いるライブラリとしてscikit-learnもインストールしておきます。
pip install mlflow scikit-learn
これでMLflowのインストールは完了です。 ここでは Linux にインストールした場合を想定しますが、基本的には他の OS でも同様の使い方ができます。
MLflowにはモデル管理を行うためのツールが用意されています。
GUI が使える端末で以下のコマンドを実行すると、MLflowのTracking Serverをローカルに立てることができます。
mlflow server &
このTracking Serverに情報を登録することでモデル管理を行うことができます。
コマンドを実行したのち、ブラウザでlocalhost:5000にアクセスすると、以下のようなGUIにアクセスすることができます。
次に、Irisデータセットを用いてAIモデルを作成し、それをMLflowに登録するプログラムを動かします。
Irisデータセットとは、3種類のアヤメの花のがくの長さと幅、花弁の長さと幅をまとめたデータセットです。 今回はこのデータセットを用いて花のがくの長さと幅、花弁の長さと幅からアヤメの花の種類を予測するモデルを作成します。 Irisデータセットがどのようなデータセットなのか具体的に知りたい場合は、以下のプログラムを実行することで詳細を確認することができます。 データセットの説明や特徴量の種類などをターミナル上に表示します。
import random
from sklearn import datasets
# Load the Iris dataset
iris_dataset = datasets.load_iris()
print("IRISデータセットの説明")
print(iris_dataset.DESCR)
print()
print("IRISデータセットの特徴量(入力)の一覧")
print(iris_dataset.feature_names)
print()
print("IRISデータセット中のアヤメの種類(予測結果)の一覧")
print(iris_dataset.target_names)
print()
print("IRISデータセットのデータ数")
print(len(iris_dataset.data))
print()
print("IRISデータセットの実際のデータを1つ出力")
# ランダムに1つ、実際の特徴量と正解データを出力する
random_idx = random.randrange(len(iris_dataset.data))
random_iris_data = iris_dataset.data[random_idx]
random_correct_index = iris_dataset.target[random_idx]
random_correct_name = iris_dataset.target_names[random_correct_index]
feature_names = iris_dataset.feature_names
for feature_name, feature in zip(feature_names, random_iris_data):
print(f"{feature_name} : {feature}")
print(f"correct : {random_correct_name}")
実際にIrisデータセットを用いてロジスティック回帰モデルを学習し、その証跡をMLflowに登録するコードが以下になります。
import mlflow
from mlflow.models import infer_signature
import pandas as pd
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
# Irisデータセットのダウンロード
X, y = datasets.load_iris(return_X_y=True)
# 学習用データとテスト用データに分割
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# ハイパーパラメータ(学習に使うパラメータ)の定義
params = {
"solver": "lbfgs",
"max_iter": 1000,
"multi_class": "auto",
"random_state": 8888,
}
# 学習用データでモデルを学習
lr = LogisticRegression(**params)
lr.fit(X_train, y_train)
# テスト用データで予測
y_pred = lr.predict(X_test)
# テスト用データで正解率を算出する
accuracy = accuracy_score(y_test, y_pred)
# MLflowのTracking Serverを指定する
mlflow.set_tracking_uri(uri="http://localhost:5000")
# MLflowに登録する用にMLflow QuickStartという実験名を命名する
mlflow.set_experiment("MLflow Quickstart")
# MLflowに学習のログを登録する
with mlflow.start_run():
# ハイパーパラメータを登録
mlflow.log_params(params)
# 正解率を登録
mlflow.log_metric("accuracy", accuracy)
# 何の実験だったかメモをタグとして登録する
mlflow.set_tag("Training Info", "Basic LR model for iris data")
# signatureはモデルの入力出力を明示的に定義するためのもの
signature = infer_signature(X_train, lr.predict(X_train))
# モデルを登録する
model_info = mlflow.sklearn.log_model(
sk_model=lr,
artifact_path="iris_model",
signature=signature,
input_example=X_train,
registered_model_name="tracking-quickstart",
)
# 登録したモデルを読み込んでテストデータに対して推論を行う
loaded_model = mlflow.pyfunc.load_model(model_info.model_uri)
predictions = loaded_model.predict(X_test)
iris_feature_names = datasets.load_iris().feature_names
result = pd.DataFrame(X_test, columns=iris_feature_names)
result["actual_class"] = y_test
result["predicted_class"] = predictions
# 推論結果を4件表示する
print(result[:4])
このプログラムの最後には、実際に4つのデータに対して推論を行った結果を表示する部分があります。 以下は実際にプログラムを動かした際のターミナルの出力例です。
sepal length (cm) sepal width (cm) petal length (cm) petal width (cm) actual_class predicted_class
0 6.1 2.8 4.7 1.2 1 1
1 5.7 3.8 1.7 0.3 0 0
2 7.7 2.6 6.9 2.3 2 2
3 6.0 2.9 4.5 1.5 1 1
actual_classは正解データ(正解データとなるアヤメの花の種類の番号)、predicted_classはAIによる推論結果です。4つのデータすべてにおいて予測結果と推論データは同じであり、AIモデルが結果を正確に推論できていることがわかります
このプログラムを実行した後localhost:5000に再度アクセスすると、AIモデルの学習を行った際の履歴を確認することができます。
実際にそのうち1つの履歴を確認すると学習を行った日付や付加されたタグ、学習時のパラメータを確認できます。
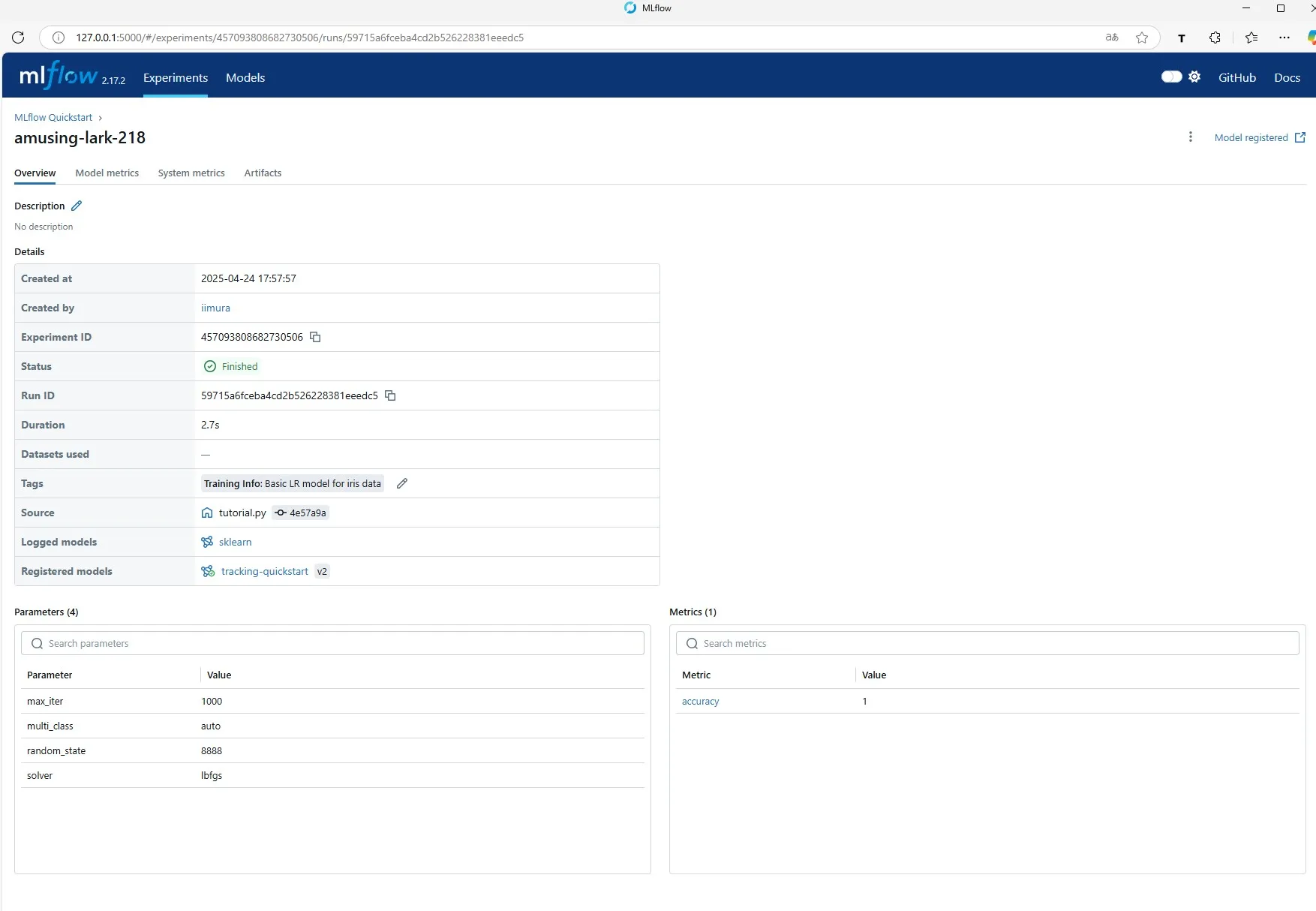
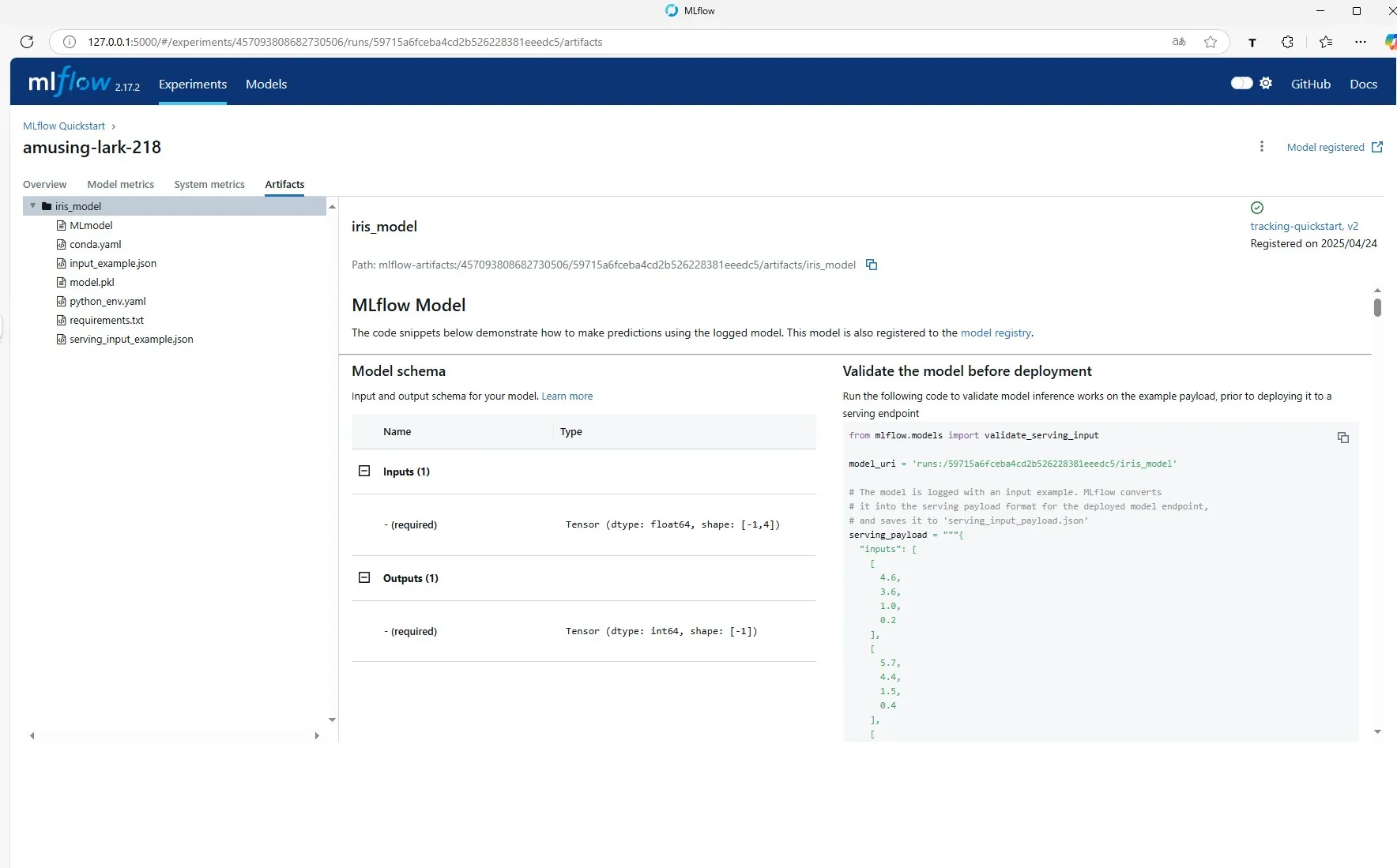
モデル本体の情報を確認することもできます。
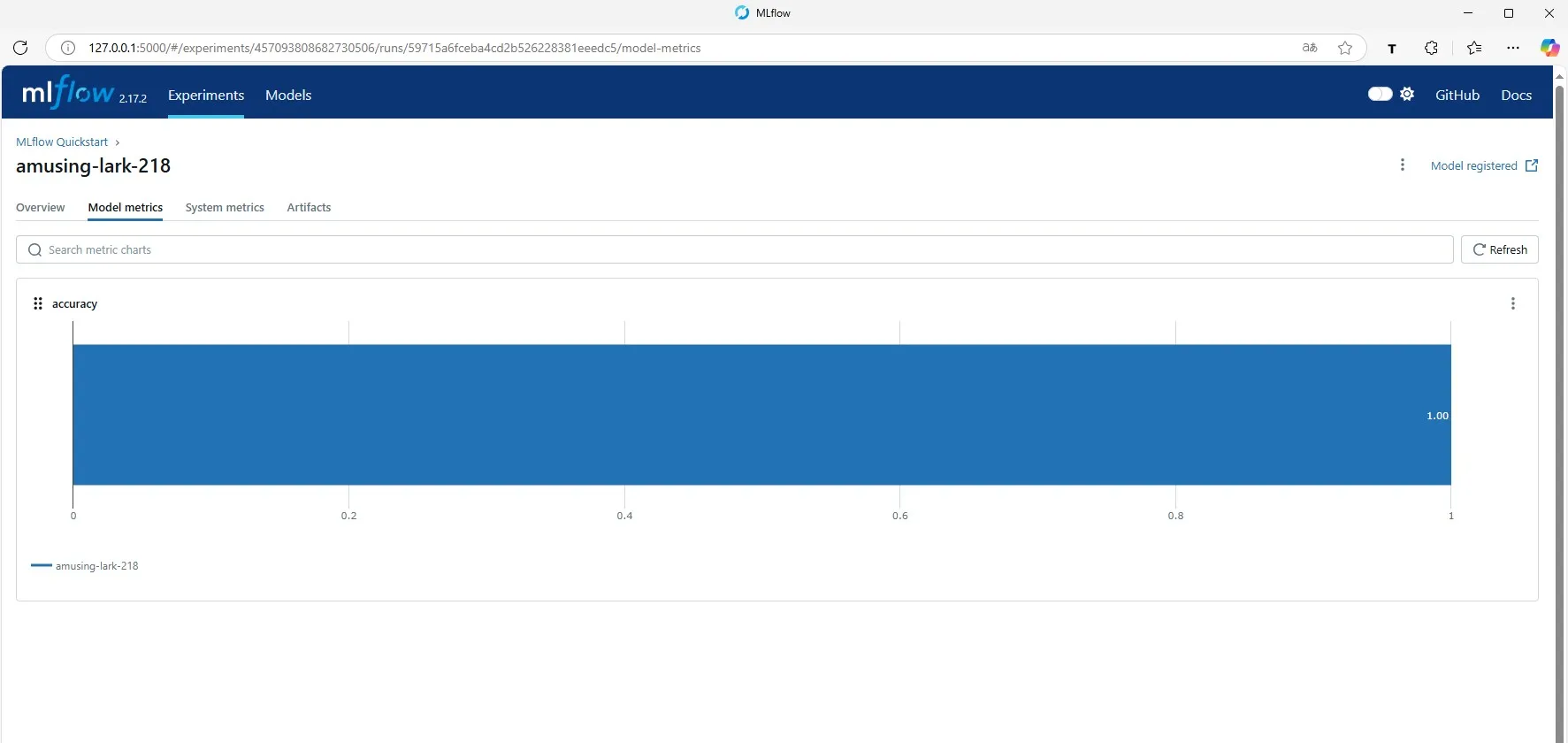
モデルの精度も記録に残っているため、後からモデル間で精度を比較することも可能です。
このようにMLflowを用いることで、AIモデルやその学習環境を管理することができるようになります。
最後に、私がMLflowのクイックスタートを動かした際の環境を以下に記します。
| ツール | バージョン |
|---|---|
| OS | Ubuntu20.04 |
| Python | 3.8.10 |
| pip | 24.0 |
| MLflow | 2.17.2 |
| scikit-learn | 1.2.2 |
おわりに
今回は、MLOps とは一体どういったものなのかご説明しました。実際に弊社ではMLflowをはじめとする様々なツールを用いて画像・映像に関連するMLOpsシステムを構築しています。 MLOpsの導入や改善についてご相談がございましたら、ぜひお気軽にお問い合わせください。