
はじめに
はじめまして、CRO技術部の小松原です。
今回はパートナー企業であるEdgeCortix社のAIアクセラレータ「SAKURA-II」を使用し、物体検知の推論を行いました。

本稿では、SAKURA-IIを用いた物体検知の実施フローをご紹介します。
SAKURA-IIを活用したエッジAIソリューションの需要
SAKURA-IIの高いエネルギー効率とリアルタイム推論性能を活かすことで、現場に設置された小型エッジデバイス上でのAI処理が可能になります。
たとえば、製造工場や物流倉庫など、通信環境が確保しにくい場所においても、SAKURA-IIを搭載した端末がローカルで物体検出・分類を行い、即座に判断を下すことができます。
エッジAIソリューションはクラウド等の外部の計算リソースとの通信を必要とせず、ローカルで処理が完結します。このため、通信コストの削減やリアルタイム性の向上につながり、セキュリティ面でも優位性があります。
SAKURA-II について
「SAKURA-II」の技術的な特徴についてご紹介します。
提供形態はM.2カードとPCIeボードが用意されており、小型で省電力ながらも高性能な推論処理が可能な、エッジAI向けのアクセラレータカードです。
M.2カードにはチップが1個搭載されています。PCIeボードにはチップが1個搭載されたSingleと2個搭載されたDualがラインナップされています。
今回はM.2カードとPCIeボード(Single)を使用しました。
また、開発環境は MERA(メラ) と呼ばれており、MERAを用いることで既存のAIモデルをSAKURA-IIでの推論に最適化することができます。

性能表
| 項目 | 性能値 | ポイント |
|---|---|---|
| 演算性能 | 60TOPS(INT8)、30TFLOPS(BF16) | 1秒あたり600億回の整数演算が可能。浮動小数点演算も対応 |
| メモリ規格 | Dual 64-bit LPDDR4X(8/16/32GB対応) | 最大32GBまで対応。複雑なビジョン・生成AIワークロードにも対応 |
| DRAM帯域 | 68 GB/sec | 高速なデータ転送で、特徴マップや重みデータ処理のボトルネックを回避 |
| オンチップメモリ | 20MB SRAM | キャッシュ的に使える高速メモリで、低レイテンシ・高効率を実現 |
| 演算効率 | 最大90% | アイドル時間が少なく、理論値に近い速度で動作 |
| 温度範囲 | -40℃ ~ 85℃ | 過酷な温度環境下でも安定動作(監視カメラ・ロボットなどに適応) |
| 消費電力(チップ) | 8W(標準値) | Jetson(※) などと比較し、大幅な省電力 |
| パッケージ | 19mm × 19mm BGA | コンパクトなチップで、組み込み基板に直接実装可能 |
※Jetson Orin Nanoシリーズは~25W程度の消費電力
対応開発環境
| 項目 | 内容 |
|---|---|
| ホストCPU | Intel / AMD x86 (64bit) |
| RAM | 最低32GB(LLM等は64GB推奨) |
| 接続スロット | PCIe Gen3 x16 / M.2 Key-M |
| OS | Ubuntu 22.04 LTS |
| 開発ツール | MERA Compiler Framework 2.2以上 |
| 対応MLフレームワーク | PyTorch、ONNX、TensorFlow Lite |
| モデルソース | Hugging Face または EdgeCortix Model Library |
今回はこちらからダウンロードした、ubuntu-22.04.5-desktop-amd64.isoを使用しています。
マザーボードにはmsi製のZ270-S01Aを採用しました。
実際にSAKURA-II(PCIeボード)を接続したときの写真です。

SAKURA-II 推論ロードマップ
以下の 5ステップ で推論を実行します。
M.2カードもPCIeボードも手順は変わりません。
今回はダウンロードしたMERAパッケージに用意されている/examples/yolov8/を動かします。
- BIOSの設定
- Hugepageの設定
- MERAのインストール
- SAKURA-IIを初期化
- 仮想環境に入り推論を実行する
以下に詳細な手順を示します。
1.BIOSの設定
以下の項目を全て無効にします。
| 項目 | 理由 |
|---|---|
| PCIe ASPM(Active State Power Management) | 省電力機能によるリンク不安定を防止するため |
| 4G Decoding または Above 4G Decoding | メモリマッピングの互換性を確保するため |
| BAR Resizing / Resizable BAR | メモリアクセスの誤認識を防止するため |
| Fast Boot / Fast Boot Up | PCIeボード初期化のスキップを防ぐため |
| VT-d(Intel Virtualization Technology for Directed I/O) | IOMMUとの競合を回避するため |
※PCIeボード(Dual)を使用する場合は、x8/x8 PCIeバスのbifurcation を有効にする必要があります。
以下は実際に設定した際のスクリーンショットです。
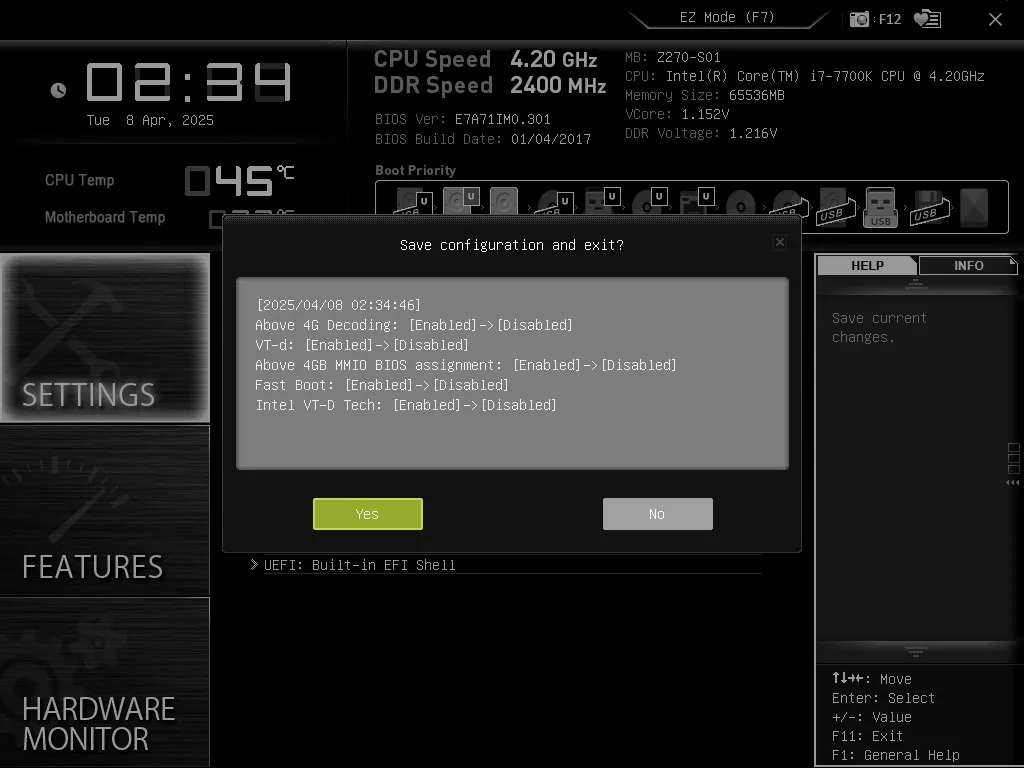
- 使用しているマザーボードはmsi製のZ270-S01Aで、BIOS Verは E7A71IM0.301 です
- BIOS上に PCIe ASPM(Active State Power Management) の設定項目が見当たらなかったため、代わりに GRUBで設定 を行いました(手順の詳細はここでは省略します)
- 同様に、BAR Resizing の設定項目もBIOS上では見つかりませんでしたが、Above 4G Decoding を Disabled にすると BAR Resizing も自動的に無効になるため、特に問題はありません
- なお、“Above 4G Decoding” と “Above 4GB MMIO BIOS assignment” は同じ機能を指しており、前者を Disabled にすると後者も連動して無効になります
- また、“VT-d” と “Intel VT-d Tech” も同様で、VT-d を Disabled にすることで両方が無効化される挙動を確認しました
マザーボードやBIOSバージョンによって設定方法が異なりますので、詳細はDeveloper Zone のドキュメントをご覧ください。
※ドキュメントの閲覧、ダウンロードには登録が必要です。
2.Hugepageの設定
SAKURA-IIが使用する大容量メモリを高速に扱うために、1GB単位のHugepageを事前に確保しておく必要があります。
以下のコマンドを使用してHugepageを設定します。
sudo sed -i 's/^\(GRUB_CMDLINE_LINUX_DEFAULT=".*\)"/\1 default_hugepagesz=1G hugepagesz=1G hugepages=4 iommu=pt"/' /etc/default/grub
sudo update-grub
sudo reboot
SAKURA-IIをマザーボードに接続し、以下のコマンドでSAKURA-IIを認識できれば問題ありません。
$ sudo lspci -nn -d 1fdc:
出力結果
01:00.0 Co-processor [0b40]: Device [1fdc:0001]
3.MERAのインストール
MERA は EdgeCortix社 の Developer Zone からダウンロードすることができます。
※ドキュメントの閲覧、ダウンロードには登録が必要です。
ダウンロードしたmera_package_v2.2.0_ubuntu22.04_20250210-0548-2.tar.gzを以下のコマンドで展開し、インストールします。
※2025年4月現在のMERA最新バージョンはv2.3.0です。
tar -xzf ~/mera_package_2.2.0.tar.gz
cd ~/mera_package/install_mera/
source install_all_steps.sh
4.SAKURA-IIを初期化
この操作は最初の一回(または再起動の度)に必要です。 以下のコマンドを実行して、カーネルドライバとデーモンをインストールして、ボードを有効化にします。
cd ~/mera_package/initialize_sakura_ii/
chmod +x setup.sh
./setup.sh
5.仮想環境に入り推論を実行する
ここまできたら後は推論を実行するだけです。
examples/yolov8 の推論スクリプトは、examples/yolov8/data/inputフォルダ内の画像(今回はhorses.jpg)に対して物体検知を行い、
結果をバウンディングボックス付きの result.png としてexamples/yolov8/に出力します。
cd ~/mera_package/install_mera/
source start.sh # 仮想環境を有効化
cd ~/mera_package/examples/yolov8/
python ./export_onnx.sh # モデル取得&ONNX形式に変換
python quantize_model.py \ # モデルの量子化
--model_path="./source_model_files/yolov8m_hardswish_finetuned_640x640.onnx" \
--coco_dir="./data/calib_images" \
--calib_imgs_num=20
python deploy.py \ # SAKURA-IIで動かせるよう最適化
--model_path="./source_model_quantized/model_qtz.mera/model.mera" \
--out_dir="./deploy_yolov8m" \
--target="ip"
python demo_model.py \ # 推論の実行
--input_path="./data/input_images/horses.jpg" \
--model_path="./deploy_yolov8m" \
--target="ip"
推論結果
出力された、examples/yolov8/result.pngを確認すると、馬を5頭検知していることがわかります。

処理時間の計測
MERAパッケージに含まれる measure.py を使用することで、SAKURA-II上での各処理ステップにかかる時間を簡単に計測することができます。
今回はYOLOv8-Mモデル(640x640、INT8量子化、MERAv2.3パフォーマンススケジューリング適用)を使用した推論処理時間の計測結果をEdgeCortix社より提供いただきました。
実測値は以下のとおりです。
| 項目 | 処理時間 | 計測内容 |
|---|---|---|
| SetInput | 0.36 ms | 入力データをPython側で整形・転送準備するのにかかった時間 |
| DMA | 1.70 ms | 入力データをホストPC → SAKURA-IIへDMA転送するのにかかった時間 |
| DNA IP | 9.53 ms | 実際にSAKURA-II上のアクセラレータでモデルの推論を実行するのにかかった時間 |
| CPU_Reorder | 0.73 ms | 出力データの並び替え・フォーマット変換などにかかった時間 |
| CPU_Ops | 0.62 ms | 補助的な処理(例:スコアの加工、閾値判定など)などにかかった時間 |
| EndToEnd 合計 | 12.58ms | 推論1回にかかった総合処理時間(SetInputを除く) |
考察
- 入力画像の準備(SetInput)やDMA転送にかかる時間も非常に短く、全体で約 12.58ms/枚という高速な推論が可能
- 1枚あたりの処理時間から換算すると、理論上のスループットは 約79 FPS(= 1000 ÷ 12.58)と高性能
所感&まとめ
たった5ステップで推論環境を整えることができ、モデル形式の細かい違いに悩まないでよいMERAパッケージは、かなり実用的と感じました。
SAKURA-II用にモデルを作り直す必要がなく、ONNXなどの既存のモデルをそのままMERAでコンパイル可能である点は開発者にとって嬉しいのではないでしょうか。
「エッジAIデバイスを使用した推論環境の構築は複雑で難しく、ハードルが高い」というイメージが良い意味で裏切られた、そんな体験になりました。
EdgeCortix社製SAKURA-IIの高いエネルギー効率とリアルタイム推論性能を活かしたエッジAIソリューションに期待ができそうです。
最後に
EdgeCortix社とアイベックステクノロジーのパートナーシップは5年前に遡ります。
AIを得意とするEdgeCortix社と、映像分野に強みを持つ当社が協力し、互いの得意分野を活かすことで、FPGAを活用したAI×映像ソリューションを展開してまいりました。
さらに、当社の製造ノウハウを活かしたEdgeCortix社製品の開発支援を行うなど、技術面での連携も深めています。
今後も両社間の情報交換を通じて、友好関係を深め、FPGA×AI×映像ソリューションの新たな可能性を切り拓いてまいります。